1. 为何现代系统离不开 IOMMU?
在计算机体系结构中,CPU 并非唯一能够发起内存访问的单元。高性能外设,如 GPU、NPU(神经网络处理单元)、NVMe 存储控制器、高性能网卡以及各种 PCIe 设备,都需要直接、高效地与系统主存进行数据交换。这种不经过 CPU 干预,由外设直接读写内存的技术被称为 DMA(Direct Memory Access,直接内存访问)。
然而,不受管制的 DMA 访问是一把双刃剑,它带来了性能提升的同时,也引入了严峻的挑战:
- 内存地址空间的限制与碎片化:许多外设(尤其是老旧或廉价的设备)只能处理 32 位的物理地址,这使得它们无法访问超过 4GB 物理内存的系统。此外,DMA 操作通常要求物理上连续的大块内存,但在一个长时间运行的复杂系统中,物理内存往往是碎片化的,分配大块连续内存变得异常困难。
- 严重的安全隐患:一个没有内存访问限制的 DMA 设备,无论是由于硬件故障、驱动程序中的 bug,还是恶意的固件攻击,都可能读写任意物理内存区域。这意味着它可以轻易地破坏操作系统内核的数据结构、窃取其他进程的敏感信息,甚至完全接管系统。这对于多租户的云环境或需要功能安全的汽车电子系统来说是不可接受的。
- 虚拟化环境下的设备隔离难题:在虚拟化场景中,我们希望将一个物理设备(如网卡)直接分配给某个虚拟机(VM)使用,即“设备直通”(Passthrough)。如果没有一种机制来隔离该设备,它可能会访问到宿主机(Hypervisor)或其他虚拟机的内存,彻底打破虚拟化技术构建的安全边界。
为了解决上述所有问题,IOMMU 应运而生。它是一个专门为系统中各类 DMA 设备服务的硬件单元。
IOMMU 的核心定位:它在功能上类似于 CPU 的 MMU(Memory Management Unit,内存管理单元)。CPU MMU 将 CPU 发出的虚拟地址(Virtual Address, VA)转换为物理地址(Physical Address, PA),并提供内存保护。与之相对应,IOMMU 将 DMA 设备发出的 IOVA(IO Virtual Address,输入/输出虚拟地址) 转换为系统物理地址(PA),并在此过程中提供精细的访问控制和隔离保护。
在今天的高端服务器平台(如 Intel VT-d, AMD-Vi)和复杂的嵌入式 SoC(如 Rockchip、Qualcomm、MediaTek、NVIDIA 的产品)中,IOMMU 已经成为一个不可或缺的标准组件。它不仅是提升系统稳定性与安全性的基石,也是实现高效硬件虚拟化的核心技术。
2. IOMMU 核心原理与功能深度解析
IOMMU 的功能远不止“地址转换”这么简单。它提供了一套完整的机制来管理和保护所有外设的内存访问。
2.1 功能一:地址转换 (Address Translation)
这是 IOMMU 最基本的功能。当设备驱动程序需要为 DMA 分配一块缓冲区时,操作系统内核可以从物理内存中分配若干个物理上不连续的页面。然后,IOMMU 驱动负责将这些离散的物理页面,在 IOVA 空间中映射成一块虚拟上连续的地址区域。
- 设备视角:设备驱动将这块连续的 IOVA 地址和长度编程到设备的 DMA 控制器寄存器中。设备在发起 DMA 传输时,只需像访问一块连续内存一样,简单地增加其内部的地址计数器即可。它完全感知不到底层物理内存的碎片化状态。
- IOMMU 视角:当 IOMMU 硬件接收到来自设备的、携带 IOVA 的 DMA 请求时,它会查询内部维护的页表(IOMMU Page Tables)。这个页表记录了 IOVA 到 PA 的映射关系。IOMMU 通过查表,将 IOVA 实时地翻译成正确的物理地址,然后将该请求转发给内存控制器。
带来的好处:
- 解决内存碎片化:极大地提高了内存利用率,使得为需要大缓冲区的设备(如 4K/8K 视频编解码器)分配内存成为可能。
- 突破 32 位地址限制:即使一个设备本身只能发出 32 位地址,IOMMU 也可以通过页表将其映射到 64 位物理地址空间的任意位置,使其能够访问远超 4GB 的系统内存。这个过程对设备自身是透明的。
2.2 功能二:内存隔离与保护 (Isolation and Protection)
这是 IOMMU 最重要的安全功能。通过为每个设备或每组相关的设备创建一个独立的地址空间(称为 IOMMU Domain),IOMMU 实现了硬件级别的隔离。
- Domain(域)的概念:一个 IOMMU Domain 拥有一套独立的 IOMMU 页表。内核可以为系统中的一个或多个设备创建一个 Domain。附着(Attach)到同一个 Domain 的设备共享同一套 IOVA->PA 映射。
- 隔离机制:
- 边界检查:设备驱动只为合法的 DMA 缓冲区建立了 IOVA 映射。如果设备试图访问一个未被映射的 IOVA 地址(无论是无意中的越界访问还是恶意攻击),IOMMU 在页表查询中会发现没有对应的有效条目,此时它会立即阻止这次内存访问。
- 权限控制:IOMMU 页表项(Page Table Entry, PTE)中通常包含访问权限位,如“可读”(Read)、“可写”(Write)、“可执行”(Execute,较少见)。内核可以根据 DMA 的方向(如 DMA_TO_DEVICE 是写操作,DMA_FROM_DEVICE 是读操作)来设置相应的权限。如果一个设备试图向一个只读的 IOVA 区域写入数据,IOMMU 同样会阻止该操作。
- IOMMU Fault(故障):当上述任何一种非法访问发生时,IOMMU 会硬件上拦截该请求,并向 CPU 发出一个中断信号,我们称之为 IOMMU Fault。内核中的 IOMMU 驱动会响应该中断,收集故障信息(如哪个设备、访问的 IOVA 地址、访问类型等),并将其打印到内核日志(dmesg)中。这为调试驱动 bug 提供了至关重要的线索。
2.3 功能三:中断重映射 (Interrupt Remapping)
除了内存访问,中断也是设备与 CPU 交互的重要方式。在没有中断重映射的系统中,设备发出的中断信号(通常是 MSI/MSI-X)直接路由到系统中的某个 CPU。在虚拟化环境中,这是极其危险的。一个被直通给虚拟机的设备,可能会伪造中断信息,向宿主机注入恶意中断,干扰甚至攻击宿主机或其他虚拟机。
IOMMU(特指 Intel VT-d 和 AMD-Vi 等服务器级实现)提供了中断重映射功能。
- 工作原理:系统中的所有中断请求不再直接发送给中断控制器,而是首先被 IOMMU 截获。IOMMU 会查询一个独立的中断重映射表(Interrupt Remapping Table)。该表由宿主机内核安全地管理,它定义了每个设备发出的中断应该被路由到哪里,以及其有效性。
- 带来的好处:
- 虚拟化安全:宿主机可以确保直通设备产生的中断只能被路由到所属的虚拟机,而无法影响宿主机或其他客户机。
- 中断隔离:防止设备间的中断干扰,增强了系统的整体稳定性。
2.4 系统中的位置
IOMMU 在现代计算机体系结构中的位置:
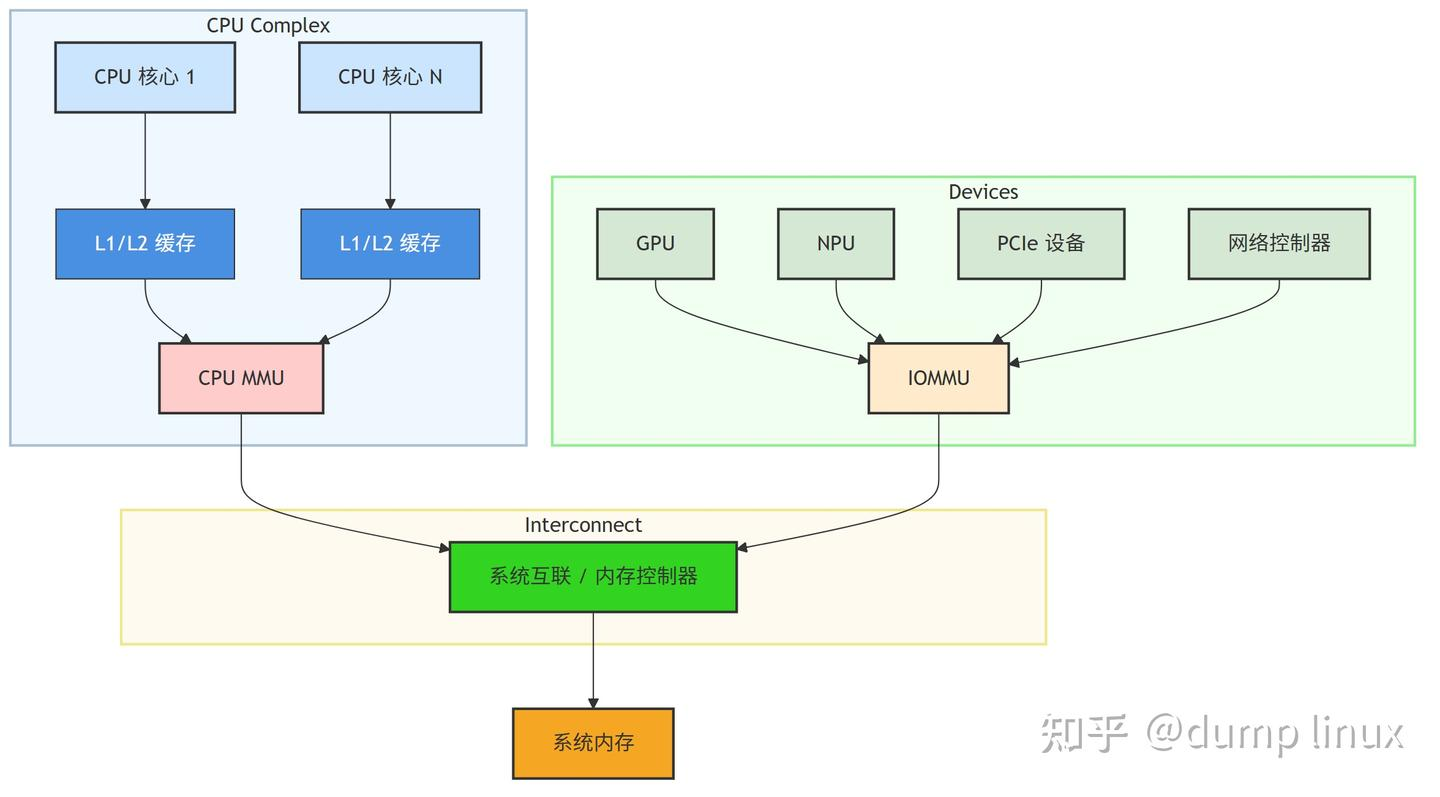
关键解读:
- 双路径访问:CPU 访问内存通过其自身的 MMU 进行地址转换和保护。
- 外设必经之路:所有发起 DMA 请求的高性能外设,其内存访问请求都必须强制经过 IOMMU。IOMMU 是它们访问系统内存的唯一网关。
3. Linux IOMMU 子系统架构的深度剖析
为了避免为每一种 IOMMU 硬件都重写一套复杂的管理逻辑,Linux 内核设计了一个通用、分层的 IOMMU 框架。这个框架极大地简化了厂商 IOMMU 驱动和设备驱动的开发。
3.1 架构分层视图
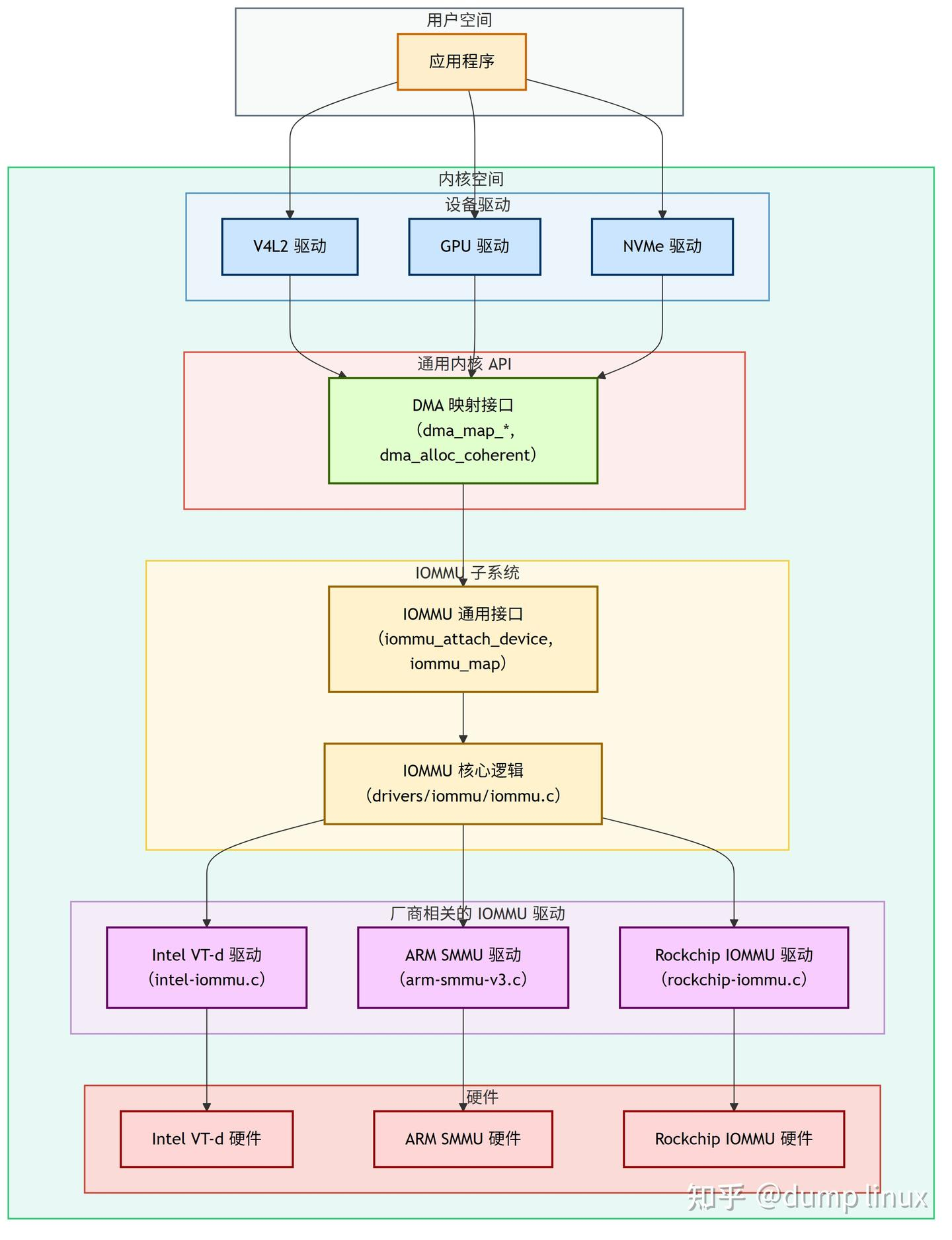
各层职责详解:
1️⃣ 设备驱动 (Device Drivers):这是 IOMMU 功能的最终“消费者”。绝大多数设备驱动并不直接与 IOMMU API 交互。它们使用的是更高层次、更通用的 DMA Mapping API。例如,当一个网卡驱动需要准备一个接收缓冲区时,它会调用 dma_map_single()。这个 API 在底层会自动处理 IOMMU 相关的映射操作。这种设计使得设备驱动可以独立于具体的 IOMMU 硬件。
2️⃣ DMA Mapping API (dma-mapping.h):这是内核中为 DMA 操作提供的标准接口。当系统中存在并使能了 IOMMU 时,DMA API 的实现会自动“挂钩”到 IOMMU 子系统。例如,dma_map_single() 的内部实现会检查设备是否关联了 IOMMU,如果是,它就会调用 iommu_map() 来获取 IOVA,而不是直接返回物理地址。
3️⃣ IOMMU Core & API (iommu.h):位于 drivers/iommu/ 目录,是整个框架的核心。
- IOMMU API:提供了一组标准的函数接口,如 iommu_domain_alloc()、iommu_attach_device()、iommu_map()、iommu_unmap() 等。这些 API 被 DMA Mapping API 或其他需要精细控制 IOMMU 的子系统(如 VFIO 驱动用于虚拟化)调用。
- IOMMU Core:实现了与具体硬件无关的通用逻辑。例如,管理 iommu_domain 的分配与释放、维护设备与 Domain 的关系、管理 IOVA 地址空间的分配等。它的角色是“承上启下”,将上层的通用请求,转换为对下层具体驱动的回调调用。
4️⃣ 厂商 IOMMU 驱动 (Vendor-Specific Drivers):这是硬件厂商需要实现的部分。每个驱动都针对一款特定的 IOMMU 硬件(如 ARM SMMUv3, Intel VT-d)。其核心任务是实现 struct iommu_ops 结构体中定义的一系列回调函数。当 IOMMU Core 需要执行一个具体操作时(如映射一个页面),它就会调用厂商驱动提供的相应 map 回调函数。这个回调函数会执行真正与硬件相关的操作,比如向 IOMMU 的寄存器写入命令、更新内存中的 IOMMU 页表项。
3.2 关键数据结构
struct iommu_group: 代表一个隔离的最小单元,是硬件决定的最小隔离单元。IOMMU 隔离粒度不是单个设备,而是 iommu_group。一个 group 内的所有设备都无法被 IOMMU 隔离,它们必须在同一个 IOMMU Domain 中。这个分组由硬件拓扑决定(例如,PCIe 的 ACS,Access Control Services,能力决定了设备是否可以互相转发流量)。内核通过 iommu_group_get_for_device() 来找到设备所属的 group。struct iommu_domain: 代表一个独立的 IOVA 地址空间,拥有一套独立的页表。最常见的类型是 IOMMU_DOMAIN_DMA,用于实现前面提到的 DMA 地址转换。当为设备创建 Domain 并 attach 后,该设备的所有 DMA 行为都将受此 Domain 的页表约束。每个 Domain 就是一份 IOMMU 页表基地址 + 配置寄存器,这些配置决定了该 Domain 的虚拟地址空间 → 物理地址空间映射。struct iommu_ops: 一个函数指针结构体,是 IOMMU Core 与厂商驱动之间的“合同”。厂商驱动必须实现这些函数,以供 Core 调用。
3.3 IOMMU Group / Domain / Device 关系
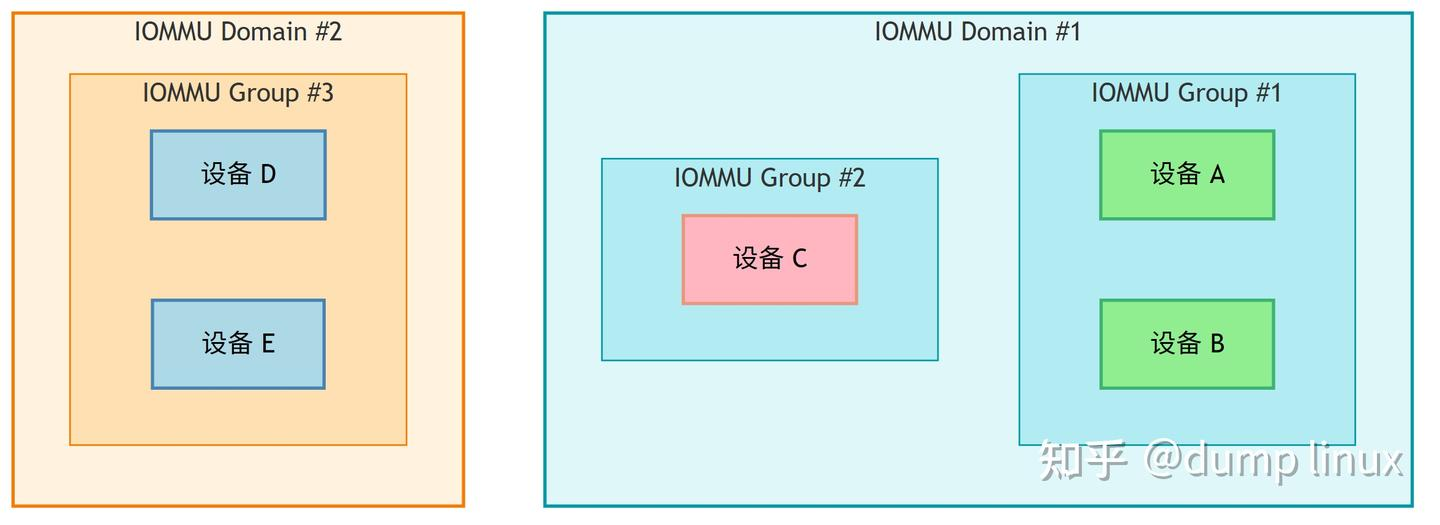
解释:
- IOMMU Domain:IOMMU 硬件中地址翻译的配置单元(一套页表),同一域内的设备共享一套页表映射规则。
- IOMMU Group:IOMMU 硬件中流控/隔离的最小单位(由 Stream ID 或 PCIe 拓扑决定),硬件上无法进一步隔离的设备集合。
- Group → Domain:一个 group 里的设备必须在同一个 domain 里。
比如:
- 设备 A 和 设备 B 在同一个 group(Group #1),所以它们必须进入同一个 domain(Domain #1)。
- 设备 C 在自己的 group,可以单独分配到同一个 Domain #1 或别的 Domain。
- Domain #2 有自己的 group(Group #3),里面的 D、E 也绑死在一起。
Domain 和 IOMMU 硬件的对应关系
在硬件和内核实现里,domain 和 IOMMU 是多对多的关系,具体取决于硬件架构:
1️⃣ 一个 IOMMU → 多个 Domain
- 常见情况:一个 IOMMU 硬件单元可以管理多个不同的 Domain,每个 Domain 有自己独立的页表、隔离规则。
- 举例:
- SoC 上的 IOMMU#1 管着 PCIe 设备、USB 控制器等,它们可能被分到不同的 Domain。
- 比如:
Domain 1:网卡 Group + USB Group
Domain 2:存储控制器 Group
这种情况下,IOMMU 里会维护多套页表。
2️⃣ 一个 Domain → 多个 IOMMU
- 较少见,但在某些多 IOMMU 架构中存在: 当多个 IOMMU 控制的设备必须共享同一套地址映射规则时,它们可以被绑定到同一个 Domain。
- 举例:
- GPU 和 VPU 分别走不同的 IOMMU 控制器,但它们要访问同一片连续的显存缓冲区(Zero-Copy)。
- 驱动会把 IOMMU#1 和 IOMMU#2 都配置到同一个 Domain,这样两边用的虚拟地址到物理地址映射是一致的。
3️⃣ 为什么不是一对一
- IOMMU 是物理硬件单元,Domain 是逻辑配置单元。
- 一个 IOMMU 可以切换、维护多套页表(即多个 Domain),而多个 IOMMU 也可以共享同一个 Domain 页表。
- 这就是为什么 VFIO 和 Linux IOMMU API 里,iommu_domain 的创建和绑定是单独调用的,而不是硬编码到某个 IOMMU 里的。
硬件拓扑关系
1️⃣ PCIe 拓扑关系
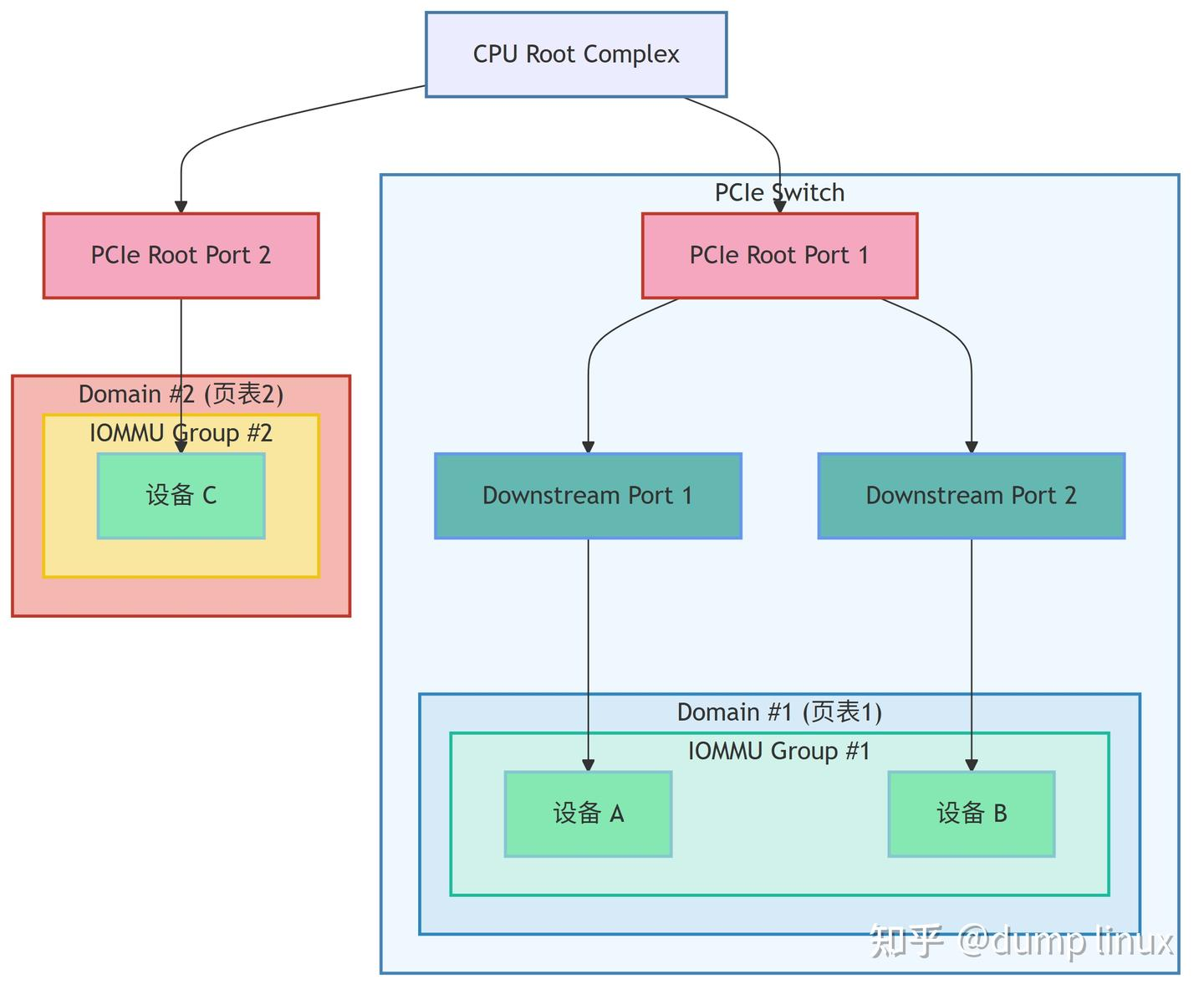
1. PCIe 拓扑决定 Group
- 一个 PCIe Switch 的下游端口如果没有独立的 ACS(Access Control Services)隔离功能,那么挂在它下面的所有设备(A、B)都会被 IOMMU 视为 同一个 Group。
- 这是因为它们共享同一条事务路径,IOMMU 无法单独拦截某一个设备的 DMA。
2. Group 是最小隔离单元
- Group #1 中的设备 A 和设备 B 必须映射到同一个 IOMMU Domain。
- 即使驱动不同,也不能给它们分配独立的页表。
3. 独立 Root Port 的设备
- 像设备 C 直接挂在 Root Port 2 上,不共享事务路径,就能独立成一个 group(Group #2)。
2️⃣ SoC 拓扑关系
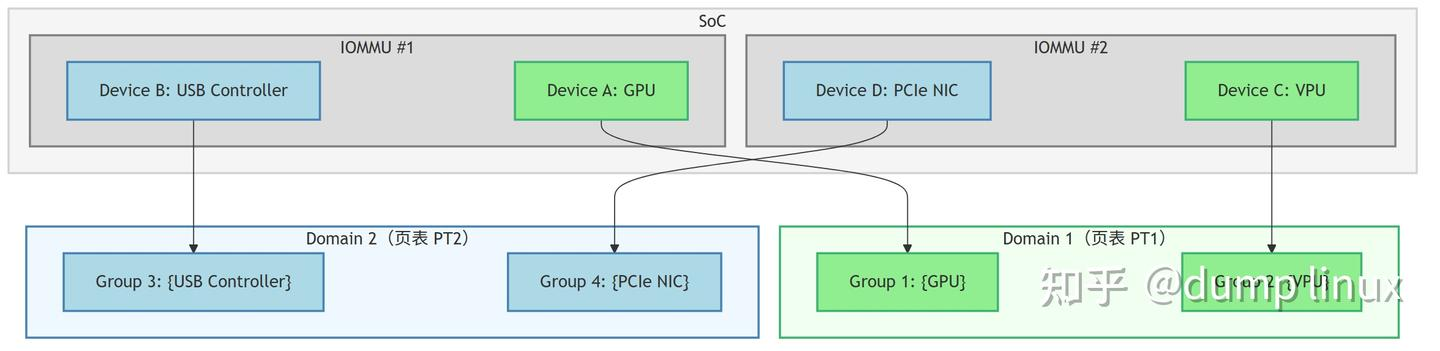
元素:
1. IOMMU
硬件模块,负责将设备发出的 DMA 地址转换成物理地址,同时也负责中断重映射。
一颗 SoC 可能有多个 IOMMU,每个负责管理一部分设备。
2. Domain
IOMMU 的配置空间,一个 Domain 对应一套页表和地址映射规则。
多个 Group 可以共享一个 Domain(前提是它们的隔离策略允许)。
3. Group
最小隔离单元,组内的所有设备在硬件上无法彼此隔离,必须被放到同一个 Domain 里。
例如同一个 PCIe 控制器下的多个 Function,可能被硬件绑在同一个 Group。
4. Device
具体的外设,比如 GPU、USB 控制器、网卡等。
说明:
-
Domain 1 绑定了 Group 1(GPU)和 Group 2(VPU),这两个组可能分别隶属于不同的 IOMMU(#1 和 #2),但共享同一套页表 PT1。
-
Domain 2 绑定了 Group 3(USB 控制器)和 Group 4(PCIe 网卡),也是类似关系,共用页表 PT2。
举例(RK3588): -
RK3588 里有多个 IOMMU(比如 SMMU1,SMMU2)分别管理不同外设组。
-
每个 SMMU 支持多个 Domain,给不同设备组分配独立或共享的地址空间。
-
设备通过硬件拓扑和 Stream ID 被划分成多个 Group。
-
多个 Group 可以在同一个 Domain 内共享映射(如 GPU+VPU)。
4. IOMMU 驱动开发实践
开发一个厂商 IOMMU 驱动,本质上就是实现 struct iommu_ops 并将其注册到系统中。
4.1 驱动的注册与初始化
IOMMU 驱动通常作为一个 platform_driver 或 pci_driver 来实现。在其 probe 函数中,核心步骤如下:
- 获取硬件资源:从设备树(Device Tree)或 ACPI 表中解析 IOMMU 硬件的寄存器地址、中断号等信息。
- 实现 iommu_ops:定义一个静态的 struct iommu_ops 实例,并将其函数指针指向自己实现的具体功能函数。
- 注册 IOMMU 设备:调用 iommu_device_register() 来注册一个 iommu_device。
- 关联设备:使用 IOMMU 设备(如 VOP)的设备树中指定该设备使用的 IOMMU,在该设备的驱动中获取 IOMMU domain 来使用 IOMMU 核心提供的 API。
// drivers/iommu/rockchip-iommu.c (示例伪代码)
static const struct iommu_ops rk_iommu_ops = {
.probe_device = rk_iommu_probe_device,
.release_device = rk_iommu_release_device,
.domain_alloc = rk_iommu_domain_alloc,
.domain_free = rk_iommu_domain_free,
.attach_dev = rk_iommu_attach_dev,
.detach_dev = rk_iommu_detach_dev,
.map = rk_iommu_map,
.unmap = rk_iommu_unmap,
.iova_to_phys = rk_iommu_iova_to_phys,
.tlb_flush_all = rk_iommu_tlb_flush_all,
/* … 其他回调 … */
};
static int rk_iommu_probe(struct platform_device *pdev)
{
// … 获取寄存器基地址、时钟、复位等 …
iommu_group_alloc();
iommu_device_sysfs_add();
iommu_device_register();
// …
return 0;
}
4.2 核心回调函数 (iommu_ops) 详解
以下是 struct iommu_ops 中最关键的几个回调函数的职责说明:
-
int (*probe_device)(struct device *dev)
- 何时调用:当一个设备被添加到 IOMMU group 时,IOMMU core 会为该 group 所属的 IOMMU 调用此函数。
- 作用:让 IOMMU 驱动有机会为特定设备进行初始化。例如,在 ARM SMMU 中,这会为设备分配一个唯一的 StreamID,并配置相关的上下文描述符。
-
struct iommu_domain *(*domain_alloc)(unsigned type)
- 何时调用:当内核需要一个新的 IOVA 地址空间时(如 iommu_domain_alloc(IOMMU_DOMAIN_DMA))。
- 作用:IOMMU 驱动需要分配并初始化其内部代表一个 Domain 的私有数据结构。对于支持多级页表的 IOMMU,这通常意味着分配页表的第一级目录(PGD)所需的内存。
-
void (*domain_free)(struct iommu_domain *domain)
- 何时调用:当一个 Domain 不再被使用时。
- 作用:释放 domain_alloc 中分配的所有资源,包括各级页表内存和私有数据结构。
-
int (*attach_dev)(struct iommu_domain *domain, struct device *dev)
-
何时调用:当一个设备需要被置于某个 Domain 的保护之下时。
-
作用:这是建立“设备”与“地址空间”关联的关键一步。驱动需要修改 IOMMU 硬件的配置,将该设备发出的所有 DMA 请求都路由到 domain 参数所指定的页表进行翻译。例如,在 ARM SMMU 中,这涉及到配置该设备的上下文描述符,使其指向 domain 的页表基地址。
-
int (*map)(struct iommu_domain *domain, unsigned long iova, phys_addr_t paddr, size_t size, int prot)
-
何时调用:dma_map_* 系列函数的核心,当需要建立一个 IOVA 到 PA 的映射时。
-
作用:这是驱动中最复杂和最核心的函数。它需要: 1. 根据 iova 和 size,在 domain 的页表中找到或创建对应的页表项(PTE)。这可能涉及到多级页表的遍历和中间页表的分配。 2. 将物理地址 paddr 和访问权限 prot(如 IOMMU_READ, IOMMU_WRITE)填入最终的 PTE 中。 3. 返回 0 表示成功,或一个负错误码。
-
size_t (*unmap)(struct iommu_domain *domain, unsigned long iova, size_t size)
-
何时调用:当 DMA 映射被释放时(如调用 dma_unmap_*)。
-
作用:清除 map 操作建立的映射。驱动需要再次遍历页表,找到对应的 PTE,并将其标记为无效。为了节省资源,驱动可以选择性地回收空的中间页表。
-
void (*flush_iotlb_all)(struct iommu_domain *domain)
-
何时调用:在 map 或 unmap 操作修改了页表之后。
-
作用:IOMMU 硬件内部通常有一个类似于 CPU TLB 的缓存,称为 IOTLB (IO Translation Lookaside Buffer),用于缓存最近的 IOVA->PA 翻译结果。修改页表后,必须使 IOTLB 中可能存在的旧缓存条目失效,否则设备可能会继续使用过期的映射。这一系列回调函数负责向 IOMMU 硬件发送 TLB 失效命令。
4.3 页表管理:驱动的灵魂
IOMMU 页表的格式由硬件架构定义(如 Intel VT-d 和 ARM SMMU 都有各自详细的规范)。驱动的 map/unmap 函数必须严格按照硬件规范来操作这些页表。
以一个典型的二级页表为例,map 操作的伪代码逻辑如下:
/*
- 这是一个简化的伪代码,用于说明 IOMMU map 操作的核心逻辑。
- 实际实现会更复杂,需要处理错误、锁、大页面等。
*/
int my_iommu_map(struct iommu_domain *domain, unsigned long iova,
phys_addr_t paddr, size_t size, int prot)
{
// 获取 IOMMU domain 的私有数据,其中包含页表基地址等信息
struct my_iommu_domain *priv_dom = domain->priv;
pgd_t *pgd; // 页全局目录指针
pud_t *pud; // 页上层目录指针
pmd_t *pmd; // 页中间目录指针
pte_t *pte; // 页表项指针
// 1. 从 domain 的页全局目录(PGD)基地址和 iova 计算出一级页表项的地址
pgd = priv_dom->pgd_base + pgd_index(iova);
// 2. 检查一级页表项 (PGD entry)。如果它不存在,意味着下一级的页表(PUD table)还未分配
if (!pgd_present(*pgd)) {
// 分配一个物理页用作 PUD table
pud_table = alloc_page(…);
if (!pud_table)
return -ENOMEM;
// 将新分配的 PUD table 的物理地址写入 PGD entry,并设置有效位等标志
set_pgd(pgd, __pgd(virt_to_phys(pud_table) | PGD_TABLE_FLAGS));
}
// 3. 计算二级页表项(PUD entry)的地址,并进行类似检查
pud = pud_offset(pgd, iova);
if (!pud_present(*pud)) {
// … 如果 PUD entry 无效,则分配 PMD table …
}
// … 经过可能的多级遍历 …
// 4. 到达最终的页表 (PTE table),计算出目标 PTE 的地址
pte = pte_offset_kernel(pmd, iova);
// 5. 填充 PTE
// 将物理地址和访问权限标志组合成一个最终的页表项值
pte_val = paddr | iommu_prot_to_pte_flags(prot);
set_pte(pte, __pte(pte_val));
// 6. 关键步骤:刷新 IOTLB
// 通知硬件页表已经改变,让相关的 TLB 缓存失效
// 这最终会调用到 iommu_ops 的 flush_iotlb_all
iommu_flush_iotlb_all(domain);
return 0; // 成功
}
4.4 设备树(Device Tree)集成
在嵌入式系统中,内核需要知道哪个设备受哪个 IOMMU 的管辖。这通过设备树中的 iommus 属性来描述。
// Rockchip RK3588 SoC 的一个例子
// 定义一个 IOMMU 控制器节点
iommu_vdec: iommu@fdab0000 {
compatible = “rockchip,iommu”;
reg = <0x0 0xfdab0000 0x0 0x10000>;
interrupts = <GIC_SPI 170 IRQ_TYPE_LEVEL_HIGH>;
clocks = <&cru PCLK_IOMMU_VDEC>, <&cru ACLK_IOMMU_VDEC>;
clock-names = “pclk”, “aclk”;
#iommu-cells = <1>; // 指定 iommus 属性需要一个 cell (Stream ID)
rockchip,page-table-size = <0x80000>;
};
// 视频解码器设备节点
vdec: video-decoder@fdac0000 {
compatible = “rockchip,rk3588-vdec”;
reg = <0x0 0xfdac0000 0x0 0x800>;
// 关键属性:此节点的第一个 iommu 是 iommu_vdec,Stream ID 是 0x1001
// Stream ID 是设备在 IOMMU 硬件中的唯一标识符
iommus = <&iommu_vdec 0x1001>;
};
当 vdec 驱动被加载时,设备驱动会解析 iommus 属性,将 vdec 设备与 iommu_vdec 关联起来,并调用 rk_iommu_ops 中的相应函数来配置 IOMMU。
5. 端到端的数据流与工作流程
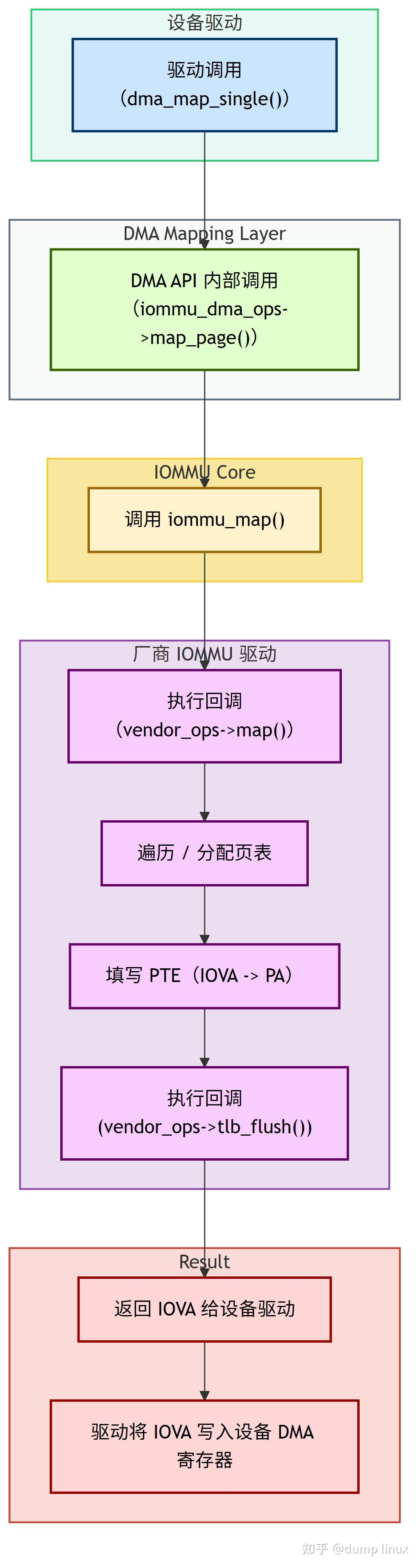
让我们将所有部分串联起来,看看一个完整的 DMA 映射和传输过程。
5.1 驱动中的 map 流程
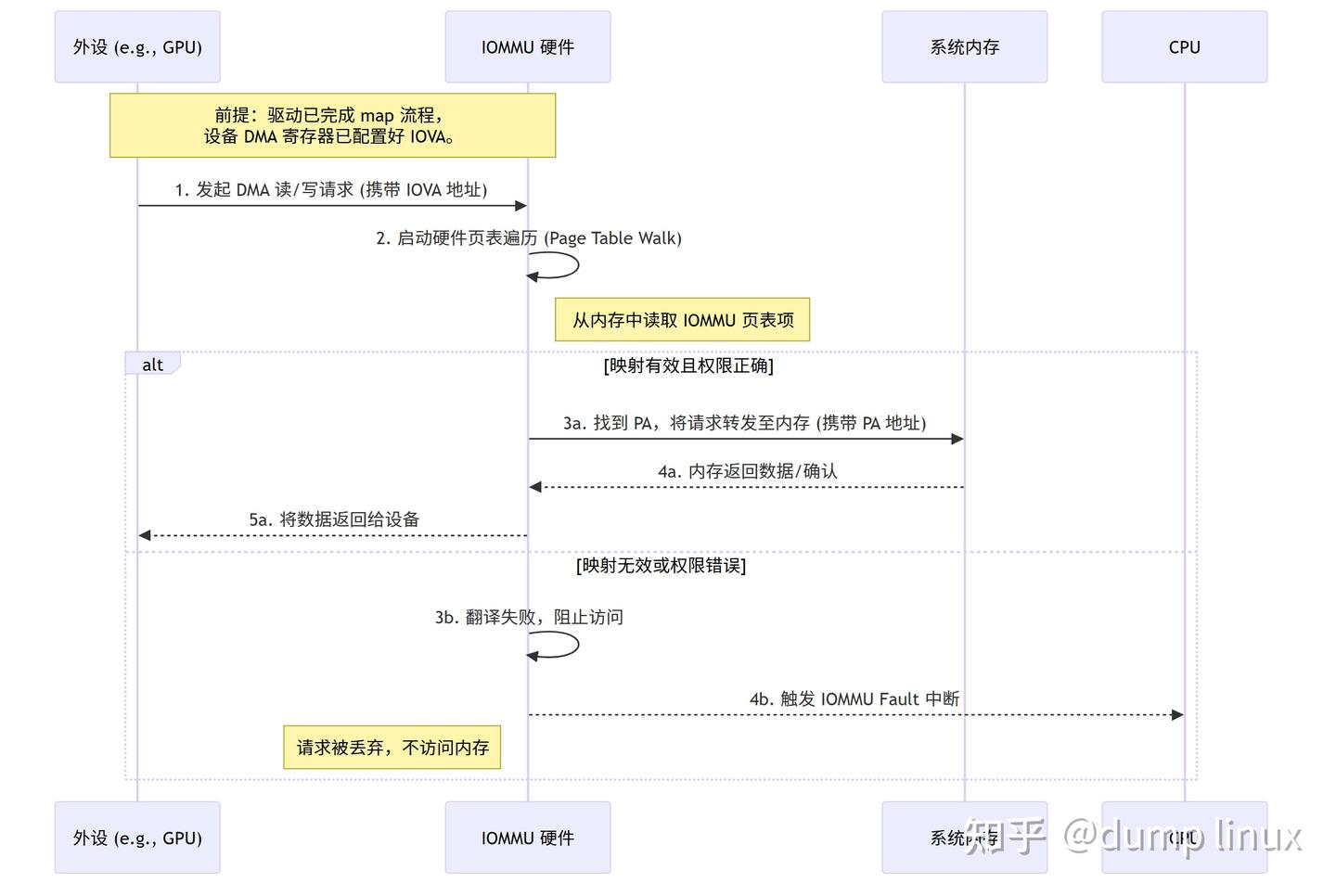
5.2 硬件 DMA 请求流程
6. 调试、验证与常见问题
IOMMU 相关的问题往往比较棘手,因为它们横跨了硬件、IOMMU 驱动和设备驱动。
6.1 内核提供的调试接口
-
debugfs (/sys/kernel/debug/iommu/): 这是最强大的调试工具。
- 不同的 IOMMU 驱动会在这里创建自己的目录,例如 intel-iommu.0 或 arm-smmu-v3.0。
- 你通常可以找到类似 pagetable 的文件,cat 它可以转储特定 Domain 的整个页表,用于检查 IOVA->PA 映射是否正确建立。
- 还可能有 iova 或 mappings 文件,显示当前已分配的 IOVA 范围。
-
sysfs (/sys/class/iommu/):
- 这里列出了系统中所有探测到的 IOMMU 设备(如 iommu0, iommu1)。
- 你可以查看每个 IOMMU 的版本、能力等信息。
- 在 /sys/kernel/iommu_groups/ 下,可以查看设备的 IOMMU 分组情况。
-
内核日志 (dmesg):
-
IOMMU Faults: 这是最直接的错误指示。当 IOMMU 故障发生时,驱动会打印详细信息,例如:
arm-smmu-v3 fde50000.iommu: Unhandled context fault: fsr=0x402, iova=0x12345000, s2fsr=0, cbndx=0, domain=0x…
这告诉你哪个 IOMMU、发生了什么类型的错误(fsr)、设备试图访问哪个 IOVA 地址。根据这个 IOVA,你可以反查是哪个驱动分配了它,从而定位问题。 -
驱动调试信息: 在厂商 IOMMU 驱动中开启 dynamic_debug 或添加 dev_dbg(),可以打印出 map/unmap 的详细过程,包括传入的物理地址、大小和返回的 IOVA。
6.2 常见错误类型与排查思路
1. IOMMU Fault (最常见)
-
原因分析:
- 悬空指针/野指针:设备驱动释放了内存 (dma_unmap_*),但设备仍在尝试使用旧的 IOVA 进行 DMA。这通常是驱动中的逻辑错误。
- 缓冲区溢出:驱动分配了 4KB 的缓冲区,但告诉设备去传输 8KB 的数据。当设备访问超出 4KB 边界的 IOVA 时,就会触发 fault。
- 映射错误:IOMMU 驱动的 map 函数有 bug,未能正确建立页表项。
- 权限错误:驱动请求了一个只读的映射 (DMA_TO_DEVICE),但设备却试图从该地址读取数据 (DMA_FROM_DEVICE)。
-
排查方法:根据 dmesg 中的 fault 信息,重点审计产生该 IOVA 的设备驱动代码,检查其 DMA 操作的生命周期管理和大小计算。
2. TLB 未及时刷新
- 症状:unmap 一个 IOVA 并立即 map 同一个 IOVA 到一个新的物理地址,但设备仍然访问到旧的物理地址。
- 原因分析:IOMMU 驱动在修改页表后,没有正确地、同步地使其 IOTLB 失效。
- 排查方法:审查 IOMMU 驱动的 map/unmap 函数,确保在修改 PTE 之后,调用了正确的 TLB flush 回调,并且该 flush 操作是阻塞的(即确保在函数返回前,硬件 flush 操作已完成)。
3. CPU 缓存与 DMA 一致性问题
- 症状:设备 DMA 写入内存后,CPU 读取到的数据是旧的;或者 CPU 写入数据后,设备 DMA 读走的数据是旧的。
- 重要提醒:IOMMU 不解决缓存一致性问题! 这个问题源于 CPU Cache 和系统内存之间的数据不一致。
- 解决方法:严格遵守 DMA API 的使用规范。
- 在设备即将读取内存前,调用 dma_sync_single_for_device(),确保 CPU Cache 中的数据被写回到主存。
- 在设备已写入内存后,CPU 即将访问该内存前,调用 dma_sync_single_for_cpu(),使 CPU Cache 中对应的缓存行失效,强制从主存重新加载。
6.3 性能考量与优化
-
性能开销来源:
-
页表遍历 (Page Table Walks):每次 IOTLB 未命中时,IOMMU 硬件都需要从主存中读取多级页表项,这个过程会带来显著的延迟。
-
TLB 管理:频繁的 map/unmap 操作会导致大量的 TLB flush 命令,增加了总线流量和管理开销。
-
内存占用:IOMMU 页表本身也需要占用一定的系统内存。
-
优化方法:
- 使用大页面 (Huge Pages):如果 IOMMU 和驱动都支持,使用 2MB 或 1GB 的大页面进行映射。一个大页面条目可以覆盖更大的地址范围,从而极大地减少 IOTLB 的压力和未命中率。
- IOVA 缓存:对于频繁分配和释放固定大小缓冲区的场景,驱动可以实现一个 IOVA 缓存池,复用已经建立好的映射,避免重复的 map/unmap 开销。
- 硬件能力:更先进的 IOMMU 有更大的 IOTLB、支持 IOTLB 预取(Prefetching)和更快的页表遍历引擎,这些都是提升性能的基础。
7. 高级主题与未来展望
7.1 IOMMU 与虚拟化 (VT-d / AMD-Vi)
IOMMU 是实现设备直通 (Passthrough) 的核心技术。当把一个物理 PCIe 设备(如一个 GPU)分配给虚拟机时,Hypervisor 会:
- 为该虚拟机创建一个专用的 iommu_domain。
- 将该 GPU 设备 attach 到这个新的 Domain。
- 虚拟机内部的操作系统(Guest OS)像往常一样使用自己的驱动程序。Guest OS 的驱动认为它在操作物理地址,但实际上 Hypervisor 已经将这些“客户机物理地址”通过 IOMMU 页表,映射到了真正的“主机物理地址”。
IOMMU 保证了该 GPU 的所有 DMA 操作都被限制在其所属虚拟机的内存范围内,无法触及宿主机或其他虚拟机的内存,从而实现了安全、高性能的硬件直通。
7.2 共享虚拟内存 (Shared Virtual Memory, SVM)
在传统的模型中,CPU 的虚拟地址空间和设备的 IOVA 空间是完全独立的。程序员需要显式地在两者之间拷贝数据。
SVM 是一种更先进的模型(在 PCIe 5.0、ARM SMMUv3 和现代 GPU 中开始支持),它允许 CPU 和设备共享同一个虚拟地址空间。这意味着 CPU 分配的一个指针,可以直接被设备解引用并访问。这极大地简化了异构计算的编程模型,避免了显式的数据拷贝和 map/unmap 操作,是未来高性能计算的一个重要方向。IOMMU 在其中扮演了使能设备侧地址翻译的关键角色。
7.3 安全加固
IOMMU 是系统纵深防御体系中的一个关键硬件层。除了防止意外的内存越界,它还可以抵御特定类型的攻击:
- DMA 攻击:通过物理接口(如 FireWire, Thunderbolt, PCIe)接入的恶意设备,在没有 IOMMU 的情况下可以读取整个物理内存。IOMMU 将这些未经授权的设备隔离在空的或受限的 Domain 中,使其无法造成危害。
- 驱动漏洞利用:即使设备驱动本身存在漏洞,IOMMU 也可以将损害限制在该驱动所能访问的内存区域内,防止其破坏内核或其他关键进程。
8. 总结
IOMMU 从一个解决内存寻址和碎片化问题的辅助单元,演变成了现代计算机体系结构中不可或缺的安全和虚拟化核心。它如同外设世界的“MMU”,为所有 DMA 操作建立了一道坚固的防火墙。
- 对于系统开发者而言,理解 IOMMU 的地址转换、隔离保护和中断重映射三大核心功能至关重要。
- 对于驱动开发者而言,Linux 的分层 IOMMU 框架屏蔽了硬件的复杂性。开发工作主要集中于实现 iommu_ops 接口,特别是页表管理 (map/unmap) 和设备生命周期管理 (attach/detach)。
- 在调试实践中,必须综合运用 debugfs、内核日志和对 DMA 缓存一致性的深刻理解,才能高效地定位和解决问题。
随着物联网、人工智能和云计算的不断发展,设备数量和复杂性持续增加,对系统安全和资源隔离的要求也日益严苛。IOMMU 作为硬件层面的第一道防线,其重要性将愈发凸显,掌握其原理与实践已成为每一位底层软件工程师的必备技能。