1、ftrace/strace
ftrace是一个内核跟踪框架,可以用于在内核中添加跟踪点并收集跟踪数据。它可以用于分析内核函数的执行路径、性能瓶颈和调试问题。ftrace提供了多种跟踪选项,包括函数追踪、事件追踪和CPU追踪等。
strace常用来跟踪进程在用户态执行的系统调用流程,但不会跟踪到内核里面发生的事情。
2、kprobes/uprobes
kprobes/uprobes 机制在事件(events)的基础上分别为内核态和用户态提供了追踪调试的功能, 这也构成了 tracepoint 机制的基础, 后期的很多工具, 比如 perf_events, ftrace 等都是在其基础上演化而来。kprobes/uprobes 在 Linux 动态追踪层面起到了基石的作用。
可以说Kprobe是使用ftrace子系统来实现的一种具体的内核跟踪技术。它们的关系是Kprobe利用ftrace框架来实现在内核函数中插入钩子进行跟踪和调试。
kprobe利用指令桩原理,截获指令流,并在指令执行前后插入hook函数:
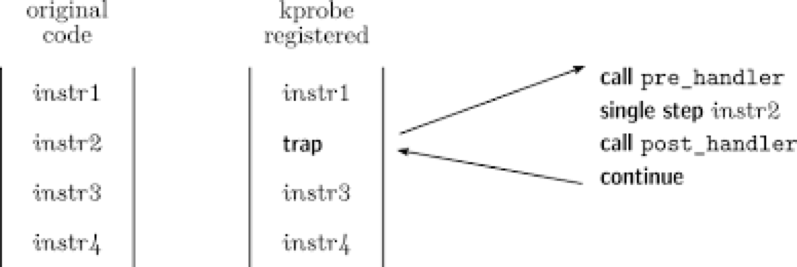
如果需要知道内核函数是否被调用、被调用上下文、入参以及返回值,比较简单的方法是加printk,但是效率低。
利用kprobe技术,用户可以自定义自己的回调函数,可以再几乎所有的函数中动态插入探测点。
当内核执行流程执行到指定的探测函数时,会调用该回调函数,用户即可收集所需的信息了,同时内核最后还会回到原本的正常执行流程。如果用户已经收集足够的信息,不再需要继续探测,则同样可以动态的移除探测点。
kprobes技术包括的2种探测手段分别时kprobe 和 kretprobe:
kprobe是最基本的探测方式,是实现后两种的基础,它可以在任意的位置放置探测点(就连函数内部的某条指令处也可以),它提供了探测点的调用前、调用后和内存访问出错3种回调方式,分别是pre_handler、post_handler和fault_handler,其中pre_handler函数将在被探测指令被执行前回调,post_handler会在被探测指令执行完毕后回调(注意不是被探测函数),fault_handler会在内存访问出错时被调用。
retprobe从名字种就可以看出其用途了,它同样基于kprobe实现,用于获取被探测函数的返回值。
https://yoc.docs.t-head.cn/linuxbook/Chapter4/tracing.html
3、perf
perf 会通过系统调用 sys_perf_event_open 在内核中注册一个监测“cycles”事件的性能计数器。内核根据 perf 提供的信息在 PMU 上初始化一个硬件性能计数器(PMC: Performance Monitoring Counter)。
perf_event_open: https://www.man7.org/linux/man-pages/man2/perf_event_open.2.html
4、eBPF
eBPF 全称 extended Berkeley Packet Filter,中文意思是 扩展的伯克利包过滤器。一般来说,要向内核添加新功能,需要修改内核源代码或者编写 内核模块 来实现。而 eBPF 允许程序在不修改内核源代码,或添加额外的内核模块情况下运行。常用的主要有bcc、bpftrace, 不过二者在嵌入式设备支持不够完善,原因在于都依赖LLVM编译器功能,用于将C代码或bpftrace代码编译成eBPF字节码,并加载到Linux内核中执行。
eBPF 的架构,如下图所示:
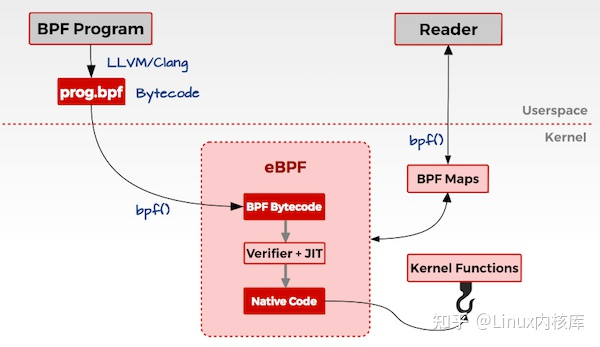
下面用文字来描述一下:
用户态
- 用户编写
eBPF程序,可以使用eBPF汇编或者eBPF特有的C语言来编写。 - 使用
LLVM/CLang编译器,将eBPF程序编译成eBPF字节码。 - 调用
bpf()系统调用把eBPF字节码加载到内核。
内核态
- 当用户调用
bpf()系统调用把eBPF字节码加载到内核时,内核先会对eBPF字节码进行安全验证。 - 使用
JIT(Just In Time)技术将eBPF字节编译成本地机器码(Native Code)。 - 然后根据
eBPF程序的功能,将eBPF机器码挂载到内核的不同运行路径上(如用于跟踪内核运行状态的eBPF程序将会挂载在kprobes的运行路径上)。当内核运行到这些路径时,就会触发执行相应路径上的eBPF机器码。
可以发现eBPF 与 Java 的AOP(Aspect Oriented Programming 面向切面编程)概念很像~
参考
https://blog.arstercz.com/introduction_to_linux_dynamic_tracing/