1.RPC介绍
RPC全称为Remote Procedure Call,意为远程过程调用。
假设有两台服务器A,B.A服务器上部署着一个应用a,B服务器上部署着一个应用b,现在a希望能够调用b应用的某个函数(方法),但是二者不在同一个进程内,不能直接调用,就需要通过网络传输,在AB服务器之间建一条网络传输通道,a把参数传过去,b接收到参数调用自己的方法得到结果,再通过网络传回给a。
简单讲就是A通过网络来调用B的过程,这个过程要涉及的东西很多,比如多线程、Socket、序列化反序列化、网络I/O,很复杂。于是大佬把这些封装起来做成一套框架供大家使用,就是RPC框架。
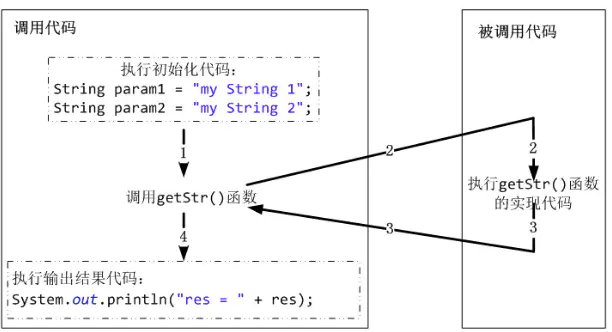
thrift通过一个中间语言IDL(接口定义语言)来定义RPC的数据类型和接口,这些内容写在以.thrift结尾的文件中,然后通过特殊的编译器来生成不同语言的代码,以满足不同需要的开发者。比如java开发者,就可以生成java代码,c++开发者可以生成c++代码,生成的代码中不但包含目标语言的接口定义、方法、数据类型,还包含有RPC协议层和传输层的实现代码。
HTTP和RPC最本质的区别,就是 RPC 主要是基于 TCP/IP 协议的,而 HTTP 服务主要是基于 HTTP 协议的。
我们都知道 HTTP 协议是在传输层协议 TCP 之上的,所以效率来看的话,RPC 当然是要更胜一筹啦!
HTTP和RPC的相同点是,底层通讯都是基于socket,都可以实现远程调用,都可以实现服务调用服务
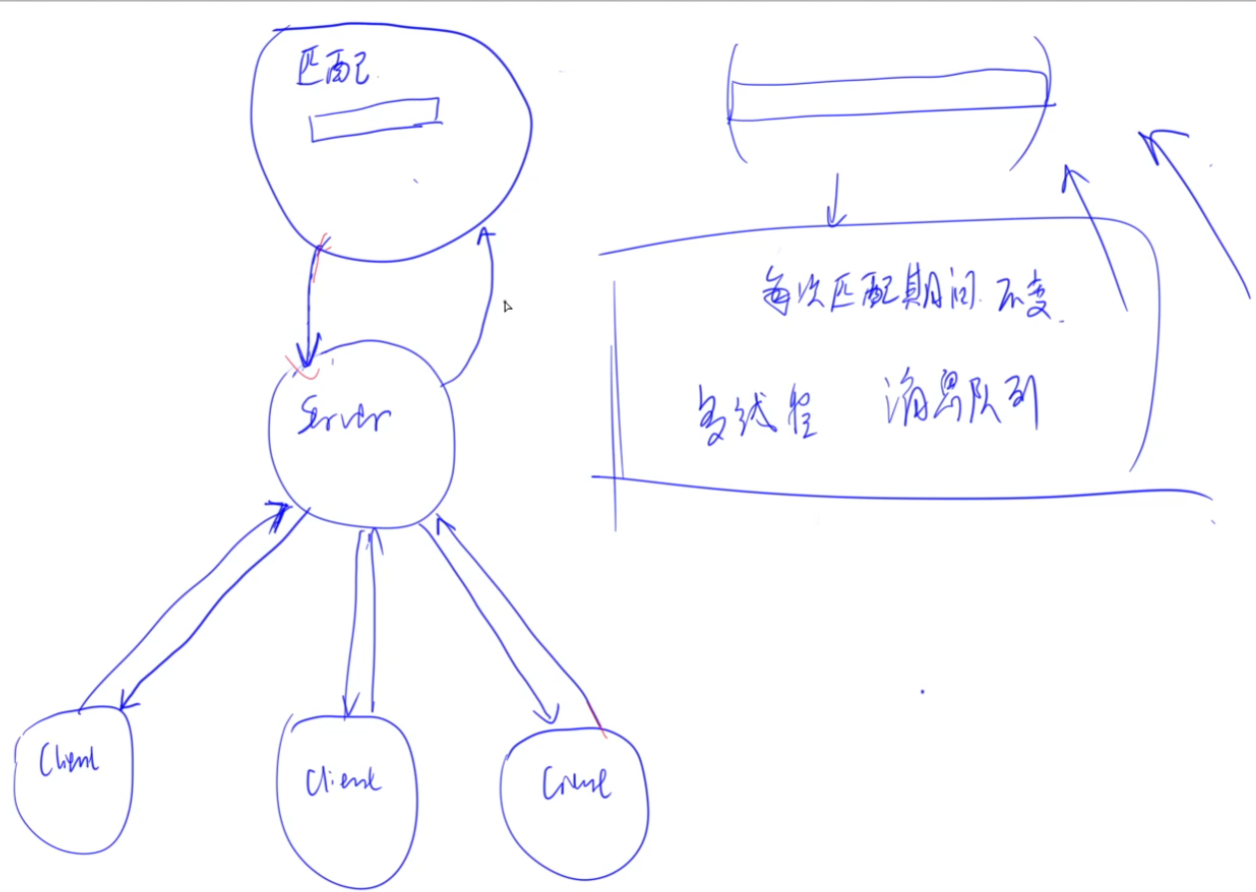
用thrift实现匹配系统的原因:
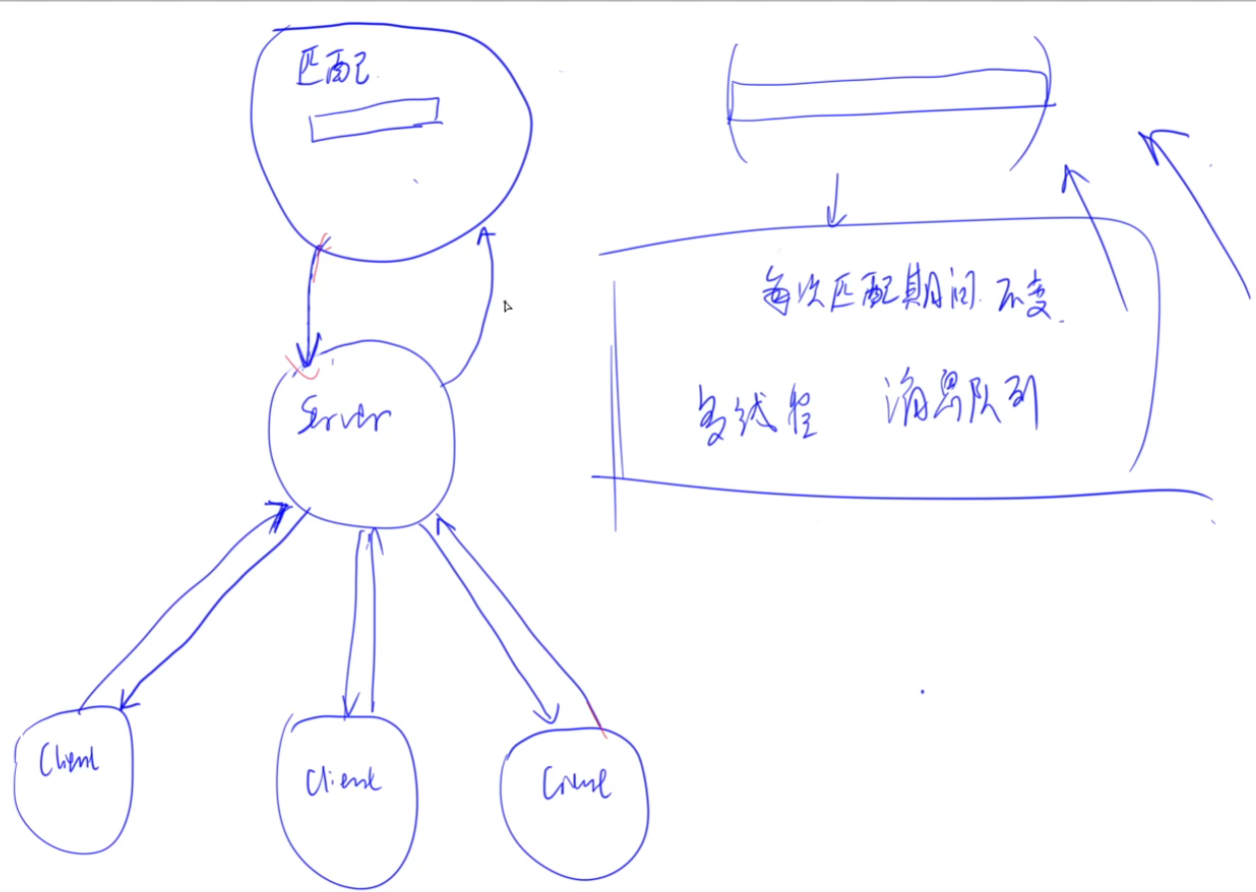
因为匹配会有延时,比如OJ评测,或者平时打车需要等待。如果这些放在server中,那么相当于连接阻塞,那么会消耗server服务器的性能,且网页卡顿。
理想的实现方式:client将信息传到server,然后连接就可以断开了。server将信息再传到匹配系统,然后匹配系统进行匹配。当匹配成功后,再通知server,然后server通知client。
因此匹配系统作为一个独立的模块,可以运行在独立的的服务器去做计算(且可以用不同语言实现,如用C++做复杂计算,速度更快)。
匹配系统与server之间的通信,使用thrift框架来实现(rpc)
2.thrift介绍
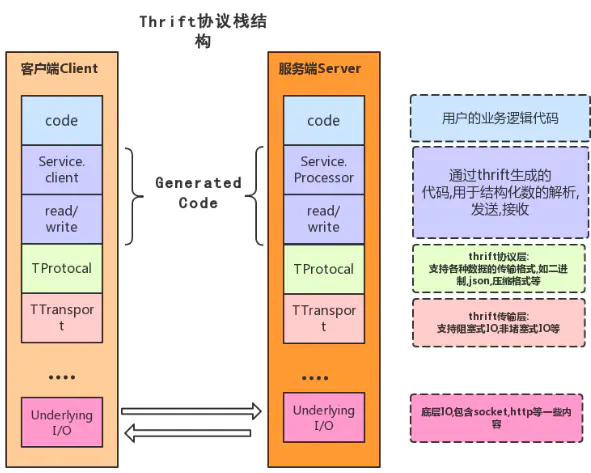
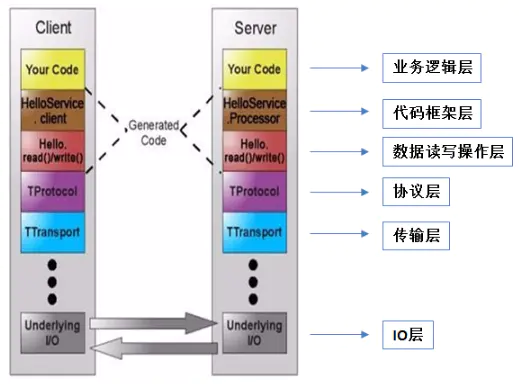
Thrift是一种c/s的架构体系。TServer主要任务是高效的接受客户端请求,并将请求转发给Processor处理。
- 最上层是用户自行实现的业务逻辑代码;
- Processor是由thrift编译器自动生成的代码,它封装了从输入数据流中读数据和向数据流中写数据的操作,它的主要工作是:从连接中读取数据,把处理交给用户实现impl,最后把结果写到连接上。
- TProtocol是用于数据类型解析的,将结构化数据转化为字节流给TTransport进行传输。从TProtocol以下部分是thirft的传输协议和底层I/O通信。
- TTransport是与底层数据传输密切相关的传输层,负责以字节流方式接收和发送消息体,不关注是什么数据类型。
- 底层IO负责实际的数据传输,包括socket、文件和压缩数据流等。
3.thrift实战理解
django项目中,匹配系统和web server在同一个服务器上,所以server通过thrift请求到匹配系统后,匹配系统直接调用了channel_layer进行了操作。正常情况应该是匹配系统返回值,然后再web server端操作channel_layer。
框架为:
client(javascript)
- webapp客户端:与web服务端交互
django server(python3)
- web 服务端
- thrift客户端a:与匹配系统交互
匹配系统(python3)
- thrift服务端a (match_server):与web server交互
在linux thrift基础课中,是有一个数据存储结点,跑在另一个服务器B上。此时在匹配系统上额外单开一个thrift作为客户端,对应的thrift server跑在服务器B上。
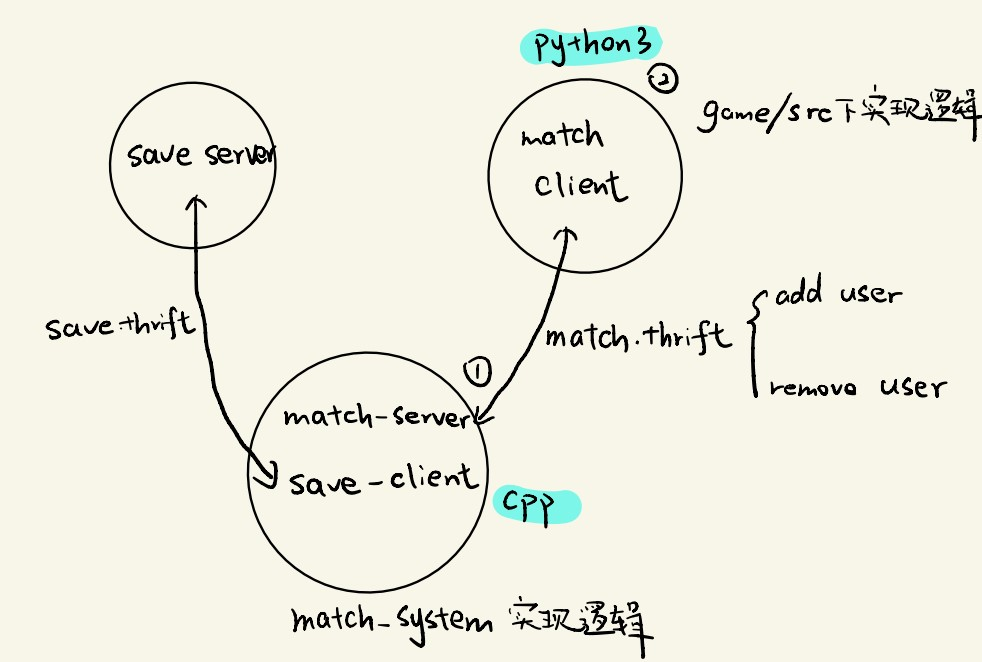
此时框架为:
游戏应用端(Python3),直接通过thrift与匹配系统交互
- thrift客户端a (match_client):与 匹配系统服务器 的服务端交互
匹配系统服务器(C++, match_system)
- thrift服务端a (match_server):与 游戏应用端 的客户端交互
- thrift客户端b (save_client):与 数据存储服务器 的服务端交互
数据存储服务器(已经实现,save_server)
- thrift服务端b:与 匹配系统服务器 的客户端交互(save.thrift)