1、问题起源
EPUB 文件格式基于 XHTML 内容和 XML 元数据的开放标准,包含在 zip 存档中(其实就是个压缩包~,可以存放文本,图片,html文件等)。
沿用之前工程中实现不加密版本epub后,在移动端epub浏览器无法直接打开,经检查发现是OEBPS文件夹中的content.opf文件内容有误。在文件中多了许多opf:前缀导致移动端无法解析epub
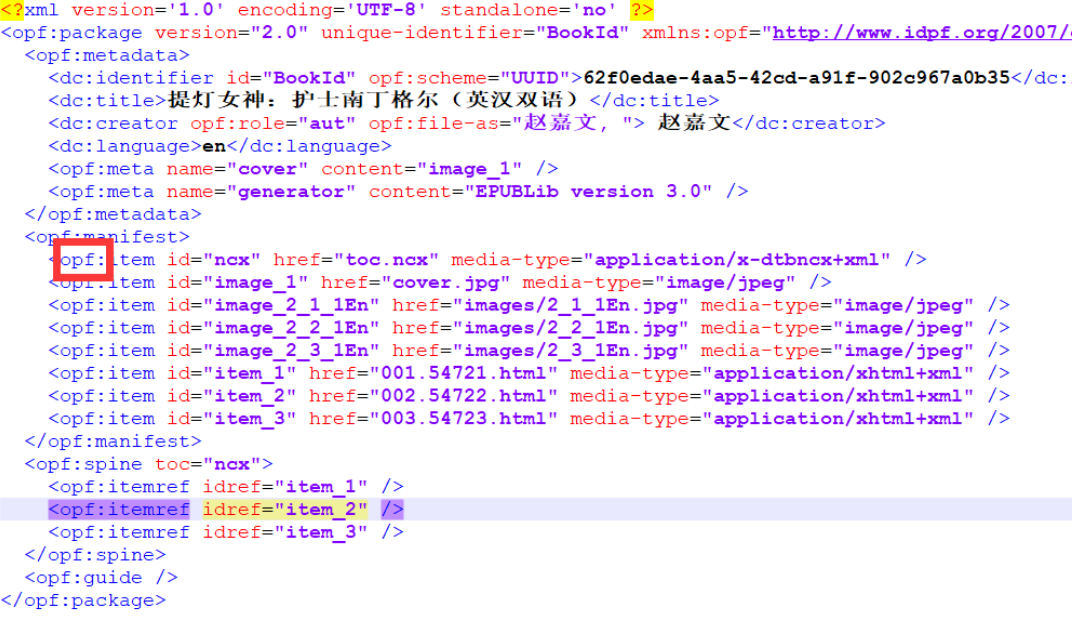
关于.opf文件 每个epub都有一个单一的包文件,它的扩展名必须为.opf,内部文件格式采用XML标准,通过包文件可以准确识别整个数字出版物的结构及阅读顺序,是解析出版物及显示ePub出版物的主要信息来源。包文件放置在名为OEBPS的文件夹下,导航文件及其他媒体文件同样存储在此文件夹中(例如书籍内容文本、CSS样式表、图像音频等)。
在查看epub文件生成过程代码的时候,发现用到了一个jar包epublib库,而生成.opf文件内容的过程正是由这个库的源代码实现的。起初想的是去理解一下.opf文件内容的填充逻辑,看着看着发现核心部分非常复杂,感觉非常难懂啊~,并且opf:和dc:是用的同一个函数生成的,还得保证dc:的逻辑不会变动,因此直接修改源码难度太大。但转念一想,这可是写好的库为什么为有这种格式问题,因此怀疑到了这个epublib库头上,转身就去github上下载了一个star数量最高的epublib库,下载下来发现它的demo中.opf文件也带有不需要的opf:,真的麻了。而且在上网搜索解决方案的时候发现关于epub的资料极少,有的也是那种好几年前的博客了。
到这里,我感觉从epublib库本身去解决这个问题行不通了,只好开启了漫长了曲线救国方案。
2、核心思想——Regex
考虑用正则匹配来去掉文件中的opf:
2.1 生成epub过程分析

因此如果能够在服务器本地还未上传到oss之前利用正则修改其中内容就能实现。因此实现思路如下:
(1) 将epub包修改后缀为zip,就可以用Linux下的命令unzip解压,然后用java代码正则即可。
然后就是这简短的一句话,中间踩了无数的坑 。。。(太菜了是这样的)
下面将一步一步记录每个细节的实现过程
3、具体实现
3.1 Java代码实现正则-Regex
主要用到java.util.regex类,能够实现指定路径下查找所有指定后缀的文件。
package com.huanke.managesystem.framework.util.uploadBook;
/**
* 2022-11-23
* rsh
* */
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.*;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Regex {
private static final Logger logger = LoggerFactory.getLogger(Regex.class);
//匹配.opf后缀文件内部类
public class FileFilter implements FilenameFilter
{
private String filterRule;
public FileFilter(String filter)
{
this.filterRule = filter;
}
@Override
public boolean accept(File dir, String name) {
if(name.lastIndexOf('.')>0)
{
// get last index for '.' char
int lastIndex = name.lastIndexOf('.');
// get extension
String str = name.substring(lastIndex);
// match path name extension
if(str.equals(this.filterRule))
{
return true;
}
}
return false;
}
}
/*
替换文件内容
传递的参数1.path文件路径,
2.patString:正则表达式(需要匹配的内容)
3.需要替换的内容
*/
public static void replace(File path,String patString2,String replacement2) {
// 正则表达式
String patt = patString2;
// 测试的输入字符串
String str="";
File file=path;
try {
FileInputStream in=new FileInputStream(file);
// size 为字串的长度 ,这里一次性读完
int size=in.available();
byte[] buffer=new byte[size];
in.read(buffer);
in.close();
str=new String(buffer,"UTF-8");
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
//System.out.println("读取到文件的信息为-----------------------------------:" + str);
// 从正则表达式实例中运行方法并查看其如何运行
Pattern r = Pattern.compile(patt,Pattern.CASE_INSENSITIVE);
Matcher m = r.matcher(str);
//System.out.println("替换成的文件为----------------------------------------------------:" + m.replaceAll("favour"));
// appendReplacement方法
m.reset();
StringBuffer sb = new StringBuffer();
while (m.find()) {
// 将匹配之前的字符串复制到sb
m.appendReplacement(sb, replacement2);
}
//sb中储存的只是匹配结束位置的信息,appendTail是加上最后未匹配到的部分文本内容,从而使内容完整
m.appendTail(sb);
//System.out.println("str是------------------------"+str);
//System.out.println("sb是------------------------"+sb);
//控制台测试
/*System.out.println(sb.toString());
m.appendTail(sb);
System.out.println(sb.toString());*/
try{
FileWriter fileWriter = new FileWriter(path);
fileWriter.write(sb.toString());
//System.out.println(sb);
fileWriter.close();
}catch (Exception e){
e.printStackTrace();
}
}
//在外部调用这个函数
public static void doRegex(String oebpsPath)
{
File f = null;
File[] paths;
//需要替换的内容
//String replacement = "from {$publicdb}.";
Regex fileFilter = new Regex();
try{
f = new File(oebpsPath);
// 文件文件名字过滤器
FilenameFilter fileNameFilter = fileFilter .new FileFilter(".opf") ;
paths = f.listFiles(fileNameFilter);
for(File path:paths){
/*
传递的参数
1.path文件路径,
2.patString:正则表达式(需要匹配的内容)
3.需要替换的内容 LEFT OUTER JOIN
*/
System.out.println("path: " + path);
logger.info("path: " + path);
replace(path, "opf:", Matcher.quoteReplacement(""));
}
}catch(Exception e)
{
e.printStackTrace();
}
}
}
在外部调用的地方,使用String.format创建一个地址字符串,然后传入doRegex即可
3.2 路径 / 与 \ 的使用区别
在Windows中,用\来分隔路径,因此要用转义'\\',而在Unix和Linux中,路径分隔符为'/',所以可以直接在路径字符串中加'/'。或者更标准的做法是用java的File类自带路径分隔符的File.separator。
logger.info("==============开始正则=================");
String regexPath = String.format("/home/backend/%s%d.zh/OEBPS", rpath, bookid);
logger.info("===========>regexPath: " + regexPath);
Regex.doRegex(regexPath);
=============> 正则测试网站1
=============> 正则测试网站2
3.3 Java代码调用Linux命令
Java可以通过Runtime.getRuntime().exec()方法调用linux平台下的命令及Shell脚本。获取命令执行结果通常有两种,一种是waitfor方法,另一种是exitValue。但waitfor方法可能造成阻塞,原因如下:
当调用exec方法后,JVM启动一个子进程,该进程会与JVM进程建立3个管道连接,即标准输入流、标准输出流、错误错误流。假设该程序不间断向标准输出流和标准错误流写数据,而JVM不读取,那么数据会暂存在Linux缓冲区中,缓冲区写满后该程序将无法继续写入,程序就会一直阻塞在waitfor方法,永远无法结束。
解决方法就是增加两个线程,一个负责读取标准输出流,一个负责读取标准错误流,这样数据就不会积压在缓冲区,waitfor方法可以正常结束。
总之,调用外部程序时需要注意以下两点:
1、如果外部程序有大量输出,需要有单独线程读取输出流和错误流
2、必须关闭3个句柄——标准输入流、标准输出流、标准错误流
考虑到阻塞问题以及为了获取命令输出,使用exitValue方法。
3.3.1 工具类ShellUtils
用于执行外部命令
package com.wll.shell;
import com.wll.utils.CommonUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
public class ShellUtils {
private static final Logger LOGGER = LoggerFactory.getLogger(ShellUtils.class);
private static final long THREAD_SLEEP_TIME = 10;
private static final int DEFAULT_WAIT_TIME = 20 * 60 * 1000;
public static void runShell(String cmd) {
String[] command = new String[]{"/bin/sh", "-c", cmd};
try {
Process process = Runtime.getRuntime().exec(command);
ShellResult result = getProcessResult(process, DEFAULT_WAIT_TIME);
LOGGER.info("Command [{}] executed successfully.", cmd);
LOGGER.info(result.toString());
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 获取命令执行结果
* @param process 子进程
* @param waitTime 指定超时时间
* @return 命令执行输出结果
*/
public static ShellResult getProcessResult(Process process, long waitTime) {
ShellResult cmdResult = new ShellResult();
boolean isTimeout = false;
long loopNumber = waitTime / THREAD_SLEEP_TIME;
long realLoopNumber = 0;
int exitValue = -1;
StreamGobbler errorGobbler = new StreamGobbler(process.getErrorStream());
StreamGobbler outputGobbler = new StreamGobbler(process.getInputStream());
errorGobbler.start();
outputGobbler.start();
try {
while (true) {
try {
Thread.sleep(THREAD_SLEEP_TIME);
exitValue = process.exitValue();
break;
} catch (InterruptedException e) {
realLoopNumber++;
if (realLoopNumber >= loopNumber) {
isTimeout = true;
break;
}
}
}
errorGobbler.join();
outputGobbler.join();
if (isTimeout) {
cmdResult.setErrorCode(ShellResult.TIMEOUT);
return cmdResult;
}
cmdResult.setErrorCode(exitValue);
if (exitValue != ShellResult.SUCCESS) {
cmdResult.setDescription(errorGobbler.getOutput());
} else {
cmdResult.setDescription(outputGobbler.getOutput());
}
} catch (InterruptedException e) {
LOGGER.error("Get shell result error.");
cmdResult.setErrorCode(ShellResult.ERROR);
} finally {
CommonUtils.closeStream(process.getErrorStream());
CommonUtils.closeStream(process.getInputStream());
CommonUtils.closeStream(process.getOutputStream());
}
return cmdResult;
}
}
3.3.2 工具类StreamGobbler
用于读取命令输出流和错误流
package com.wll.shell;
import com.wll.utils.CommonUtils;
import java.io.*;
import java.util.ArrayList;
import java.util.List;
public class StreamGobbler extends Thread {
private InputStream is;
private List<String> output = new ArrayList<String>();
public StreamGobbler(InputStream is) {
this.is = is;
}
public List<String> getOutput() {
return output;
}
@Override
public void run() {
BufferedReader reader = null;
try {
reader = new BufferedReader(new InputStreamReader(is, "UTF-8"));
String line = "";
while ((line = reader.readLine()) != null) {
output.add(line);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
CommonUtils.closeStream(reader);
}
}
}
3.3.3 ShellResult类
命令执行结果类
package com.wll.shell;
import java.util.List;
public class ShellResult {
public static final int SUCCESS = 0;
public static final int ERROR = 1;
public static final int TIMEOUT = 13;
private int errorCode;
private List<String> description;
public int getErrorCode() {
return errorCode;
}
public void setErrorCode(int errorCode) {
this.errorCode = errorCode;
}
public List<String> getDescription() {
return description;
}
public void setDescription(List<String> description) {
this.description = description;
}
@Override
public String toString() {
return "ShellResult{" +
"errorCode=" + errorCode +
", description=" + description +
'}';
}
}
3.3.4 工具类CommonUtils
由于流关闭操作用得比较频繁,可以单独写一个流操作工具类
package com.wll.utils;
import org.apache.log4j.Logger;
import java.io.Closeable;
import java.io.IOException;
public class CommonUtils {
private static final Logger LOGGER = Logger.getLogger(CommonUtils.class);
/**
* 提供统一关闭流的方法
*
* @param stream 待关闭的流
*/
public static void closeStream(Closeable stream) {
if (stream == null) {
return;
}
try {
stream.close();
} catch (IOException e) {
LOGGER.error("Close stream failed!");
}
}
}
3.3.5 举栗子
//测试zh改变.epub格式为.zip格式
logger.info("==============开始zh格式转换================");
String cmdchange = String.format("mv /home/backend/%s.zh.epub /home/backend/%s.zh.zip", fullPath, fullPath);
ShellUtils.runShell(cmdchange);
3.3.6 避坑Tips
注意这里有个坑,就是用java操作shell去执行cd指令的时候,操作系统会重新创建一个shell会话。
举个栗子
(1) java程序运行在/home/lings目录下;
(2) 希望删除/home/test目录下的文件proxy.log;
(3)调用上面的接口两次?
executeLinuxCmd("cd /home/test");
executeLinuxCmd("rm -fr /home/proxy.log");
是不行的!
因为这个接口的调用是单次事务型的,就是每次调用都是独立的事务或者说操作,没有关联的。
正确操作:
方法一: 对于不复杂的指令操作,如两条shell命令的接合,可以简单地通过&&写到一行来实现。
cd /opt/test/etc/ && zip -r test.zip *
方法二:可以写一个独立的脚本,然后一次运行脚本,这样多复杂的逻辑都没问题。
方法三:建立一个shell长连接。
这里只用到了方法一就解决了~
这样就可以实现执行简单的shell指令了。当然还有可以实现执行shell脚本文件的操作,涉及到对shell脚本文件的读取然后执行,本次没有涉及到,下次有需要在学习啦~
经过好久之后,终于成功去掉了万恶的opf:,然后发现最终的epub目录结构多了一层,导致在移动端浏览器解析的时候还是不行。。。查找资料后发现是Linux下的zip命令导致的。这里记录一下zip命令折磨人的大坑。
想要对某个文件夹进行递归压缩并且最终不会多套一层目录结构需要进入该文件夹里面进行压缩打包!!
必须先cd到相应目录。
再zip -r package.zip * <=====因为已经进入了目录,所以是*。
否则压缩文件解压后会带有路径文件夹,就离谱~
zip常见用法
(1) cd 到相关目录内,zip -r package.zip *
(2) -j 操作,能够直接将文件夹内的文件装进压缩包,而不会带有任何文件夹。
unzip常见用法
unzip的路径参数都可以是绝对路径,舒服!
unzip -d ./tmp/ ana.zip <===== -d 用于自定义解压到的路径
4、结尾
这样就彻底解决了本次项目中出现的问题啦,完结撒花❀ ,下期见了~~